
Databases (and search engines like Elasticsearch) typically store the date of birth instead of the current age. It's a simple date value instead of a calculated one which must be maintained every day. But statistics often should contain the age - which is much more pleasant for humans than the date (or year) of birth. This post shows an easy way to use the Elasticsearch date_histogram aggregation to output age buckets instead of counting users by their year of birth.
The date_histogram aggregation is very powerful. Just pass a field and interval to get buckets with the doc count per interval. An example query could be: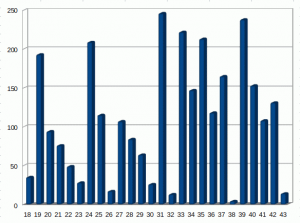
{
"aggs": {
"year-of-birth": {
"date_histogram": {
"field": "date_of_birth",
"interval": "1y"
}
}
}
}
Aggregate everything by date_of_birth and create yearly (1y = 1 year) buckets:
{
"aggregations" : {
"year-of-birth" : {
"buckets" : [
{
"key_as_string" : "1900-01-01",
"key" : -2208988800000,
"doc_count" : 25825
},
{
"key_as_string" : "1901-01-01",
"key" : -2177452800000,
"doc_count" : 1014
},
{
"key_as_string" : "1902-01-01",
"key" : -2145916800000,
"doc_count" : 269
}
]
}
}
}
In 2019, 25825 items of the test dataset are 119 years old, 1014 are 118 and 269 are 117.
But that's not true: Some of them might have celebrated their birthday already. They're counted for the wrong age.
But the date_histogram also supports an offset argument. Today is the 77th day of 2019, so the query could be:
{
"aggs": {
"year-of-birth": {
"date_histogram": {
"field": "date_of_birth",
"interval": "1y",
"offset": "+77d"
}
}
}
}
The offset changes the start of each bucket. Elasticsearch still returns yearly buckets but now they start 77 days after the beginning of the year:
{
"aggregations" : {
"age" : {
"buckets" : [
{
"doc_count" : 22534,
"key_as_string" : "1899-03-19",
"key" : -2208988800000
},
{
"key" : -2177452800000,
"doc_count" : 3899,
"key_as_string" : "1900-03-19"
},
{
"key" : -2145916800000,
"key_as_string" : "1901-03-19",
"doc_count" : 485
}
]
}
}
}
Notice that most of our test data already had their birthday. 22534 items are returned with a birth year of 1899 which means they completed 119 years of living. 3899 are in the range until the 18th of March 1901, they're 118 years but many of them still have 1990 as their year of birth. Another 485 are 117 years old.
The result might still be slightly inaccurate due to leap years which have one more day in February, but it's much more accurate than counting the year-of-birth.
The format option may be used to cut the bucket keys down to a year and the calling application still needs to calculate the age out of the bucket keys. A scripted aggregation would also be able to do that, but it would calculate the date for every item before applying the aggregation. That's a lot of overhead which could be avoided.





Noch keine Kommentare. Schreib was dazu