
ElasticSearch is a search engine. It's made for extremly fast searching in big data volumes. But sometimes one needs to fetch some database documents with known IDs. I found five different ways to do the job. Let's see which one is the best.
1. Search
The Elasticsearch search API is the most obvious way for getting documents. It's build for searching, not for getting a document by ID, but why not search for the ID?
2. Scroll
Search is made for the classic (web) search engine: Return the number of results and only the top 10 result documents. It's getting slower and slower when fetching large amounts of data.
The scroll API returns the results in packages. The application could process the first result while the servers still generate the remaining ones. It's even better in scan mode, which avoids the overhead of sorting the results.
3. Get
The most simple get API returns exactly one document by ID.
4. MGet
The Elasticsearch mget API supersedes this post, because it's made for fetching a lot of documents by id in one request. I did the tests and this post anyway to see if it's also the fastets one.
5. Exists
Not exactly the same as before, but the exists API might be sufficient for some usage cases where one doesn't need to know the contents of a document.
Quick benchmark
#!/usr/bin/perl
use strict;
use warnings;
$| = 1;
use Time::HiRes qw(time);
use Search::Elasticsearch;
my $es = Search::Elasticsearch->new(
nodes => 'es-db.lan:9200', # One cluster node
cxn_pool => 'Sniff', # Detect & use other cluster nodes automatically
) or die 'Error connecting to ElasticSearch';
my $es_index = 'raw_mail_log';
my $es_type = 'mail';
for my $cnt ( 100, 1000, 10000 ) {
my @ids = map { $_->{_id} } @{
$es->search(
index => $es_index,
type => $es_type,
fields => ['_id'],
size => $cnt,
)->{hits}->{hits}
};
my $start_ts = time;
for ( 1 .. 25 ) {
$es->search(
index => $es_index,
type => $es_type,
size => 100000,
body => {
query => {
filtered => {
filter => {
bool =>
{ must => [ { terms => { _id => \@ids } } ] }
}
}
},
}
);
}
print "$cnt ids: search: " . ( ( time - $start_ts ) / 25 );
$start_ts = time;
for ( 1 .. 25 ) {
my $scroll = $es->scroll_helper(
index => $es_index,
type => $es_type,
size => 100000,
search_type => 'scan',
body => {
query => {
filtered => {
filter => {
bool =>
{ must => [ { terms => { _id => \@ids } } ] }
}
}
},
}
);
while ( $scroll->next ) { }
}
print "$cnt ids: scroll: " . ( ( time - $start_ts ) / 25 );
$start_ts = time;
for ( 1 .. 25 ) {
for my $id (@ids) {
$es->get(
index => $es_index,
type => $es_type,
id => $id,
);
}
}
print "$cnt ids: get: " . ( ( time - $start_ts ) / 25 );
$start_ts = time;
for ( 1 .. 25 ) {
$es->mget(
index => $es_index,
type => $es_type,
body => { ids => \@ids },
);
}
print "$cnt ids: mget: " . ( ( time - $start_ts ) / 25 );
$start_ts = time;
for ( 1 .. 25 ) {
for my $id (@ids) {
$es->exists(
index => $es_index,
type => $es_type,
id => $id,
);
}
}
print "$cnt ids: exists: " . ( ( time - $start_ts ) / 25 );
}
Results
Using the Benchmark module would have been better, but the results should be the same:
1 ids: search: 0.0479708480834961
1 ids: scroll: 0.125966520309448
1 ids: get: 0.0058095645904541
1 ids: mget: 0.0405624771118164
1 ids: exists: 0.00203096389770508
10 ids: search: 0.0475555992126465
10 ids: scroll: 0.125097160339355
10 ids: get: 0.0450811958312988
10 ids: mget: 0.0495295238494873
10 ids: exists: 0.0301321601867676
100 ids: search: 0.0388820457458496
100 ids: scroll: 0.113435277938843
100 ids: get: 0.535688924789429
100 ids: mget: 0.0334794425964355
100 ids: exists: 0.267356157302856
1000 ids: search: 0.215484323501587
1000 ids: scroll: 0.307204523086548
1000 ids: get: 6.10325572013855
1000 ids: mget: 0.195512800216675
1000 ids: exists: 2.75253639221191
10000 ids: search: 1.18548139572144
10000 ids: scroll: 1.14851592063904
10000 ids: get: 53.4066656780243
10000 ids: mget: 1.44806768417358
10000 ids: exists: 26.8704441165924
Get, the most simple one, is the slowest. The get API requires one call per ID and needs to fetch the full document (compared to the exists API). Search is faster than Scroll for small amounts of documents, because it involves less overhead, but wins over search for bigget amounts. The winner for more documents is mget, no surprise, but now it's a proven result, not a guess based on the API descriptions.
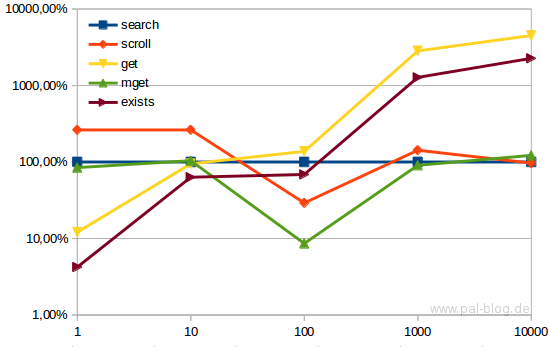 Benchmark results (lower=better) based on the speed of search (used as 100%). mget is mostly the same as search, but way faster at 100 results.
Benchmark results (lower=better) based on the speed of search (used as 100%). mget is mostly the same as search, but way faster at 100 results.





Noch keine Kommentare. Schreib was dazu